Why ITOps still suffers from alert fatigue
It takes a lot of time, effort and money to configure centralized monitoring. Making it all the more frustrating that those carefully crafted alerts will probably just end up being ignored. So why has the whole of ITOps collectively decided to banish your monitoring alerts to their junk folders? The simple answer: alert fatigue.
During this blog we discuss the reasons behind alert fatigue, but more importantly, what can you do about it. Read on to find out more.
Alert fatigue is your #1 enemy
Whilst the reasons alerts are ignored remain largely consistent, knowing where to start is a little more complex.
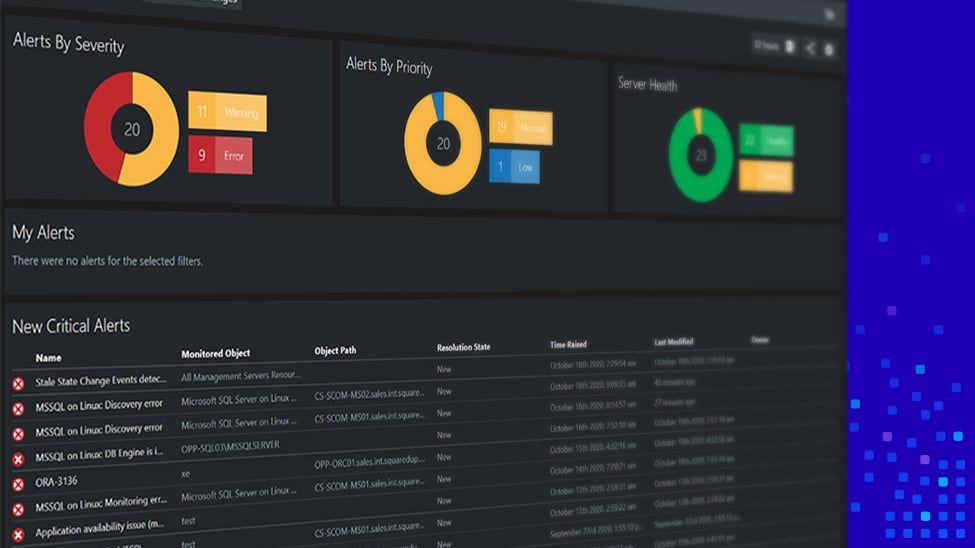
You see, centralized monitoring is often caught in the middle of a vicious cycle. Whilst they have access to a tonne of rich infrastructure data - but because it lacks context - ITOps teams don’t know what to do with it. As such, system fatigue begins to spread and bad habits creep in.
Worse still, because the user experience offered by centralized monitoring tools are often a little out-dated, consumers would rather stick to their own niche tools. Meaning centralized monitoring don’t get the insights and feedback they need to customize alerts. Meaning centralized monitoring continues to adopt this one-size-fits-all approach. Meaning centralized monitoring don’t get the insights and feedback they need to customize alerts. And so on...
Like I said, a vicious cycle.
Game shows that are impossible to win
So a few people have decided to switch off from centralized monitoring, so what? That just means ITOps can focus on their day job. No biggy.
Wrong. A big fat wrong.
We've all heard of the phrase “work smarter, not harder”, well, ignoring alerts that are designed to monitor and report on the collective good will engender a culture that does the exact opposite. With that said, I'd like to introduce you to the blame game! As you're someone who works in IT you’re probably familiar with the rules, but for those of you that are new to the game, let’s do a quick re-cap:
- Keep all your monitoring data to yourself. Under no circumstances should this be shared.
- Shift the blame wherever possible. It’s not your fault the application went down.
- Look confident and assured. Don’t give other contestants reason to sniff blood.
And finally, if you’re the one that eventually gets shafted with the blame, you’ll be crowned this week’s loser. But don’t worry, there’s always next week…
*A terrible theme tune begins to play*
Weird game show analogies aside, a divisive IT culture - whilst not a particularly nice environment to be a part of - will severely impact your end users. Unable to access the systems and services they rely on, internal and external stakeholders will quickly become frustrated with IT. Not only that, core KPIs will take a dramatic turn for the worse. Mean Time to Repair (MTTR) stats will go through the roof, the number of incidents detected by customers vs operations will begin to look ugly. Basically any KPI that can be linked back to your holiday bonus could feasibly be affected.
It’s no wonder then that 43% of business leaders believe that IT can be significantly replaced by shadow IT. After all, if IT hasn’t got a handle on how their work rolls up and contributes to the greater good – how can the business be expected to?
6 ways you can reduce your MTTR
Context is king
Following in the footsteps of marketing, it's context (not content) that rules the roost. You've already got a tonne of data - but without context - those numbers quickly become meaningless. To put a slightly different spin on this, how many times have you encountered the following scenario:
An angry business exec picks up the phone and rings IT – bypassing the ServiceDesk - he instead chooses to call his own personal contact.
A critical business application is down.
Business Exec: The CRM is down!
System Admin: It's probably a database issue. Has that fixed it?
Business Exec: No…
System Admin: OK, it could be because the disk is full? Can you access it now?
Business Exec: Nope, I still can’t get on!
System Admin: Perhaps it's this Load Balancer issue…?
Business Exec: Nope!
And so on…
Although horrifyingly simplistic (check out the Phoenix Project for better examples), I’m pretty confident this is a story that will still resonate with most. The issue has never been that we need more data, it’s knowing which data we need to focus on. Sure, some of you might have an APM tool at your disposal, but their barriers to entry (high cost, difficulty to deploy etc.) will mean their use is probably restricted to one or two key applications. Not the hundreds and thousands of apps enterprise IT are currently expected to manage.
What if I told you it is possible to map and monitor all your enterprise applications - without costing an arm and a leg? Well, today's your lucky day. As highlighted in a previous blog, thanks to its extensible nature, SCOM was recently awarded a customer choice award from Gartner in the category for APM. Now don’t get us wrong, we love SCOM, in fact, we think it’s bloody awesome – SquaredUp didn’t choose to build on top of it by chance. But the other reason we chose SCOM was because its UI is, erm, dated.
We’re firm believers the world doesn’t need more data, we just need to better understand what we already have.
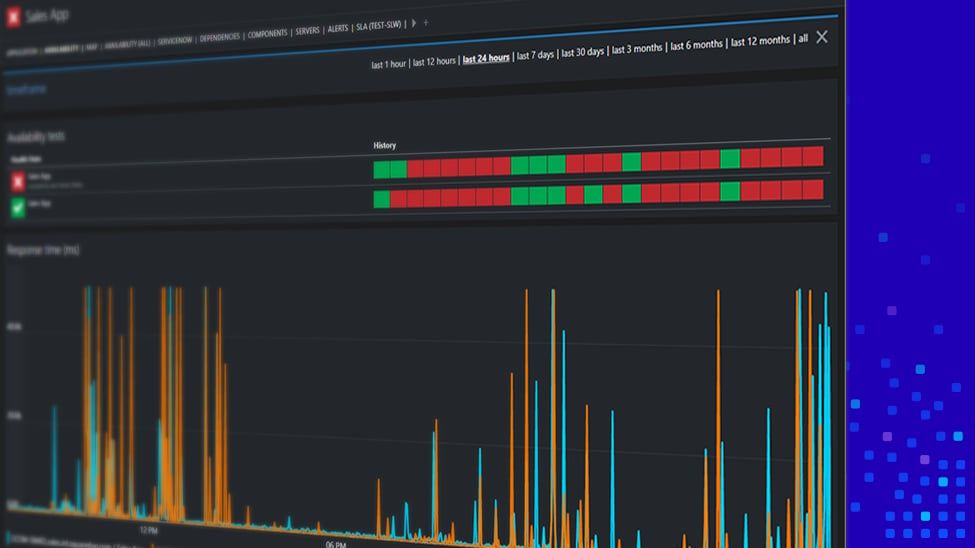
If you’re lucky enough to have SCOM, you're the proud owner of one of the most powerful infrastructure monitoring tools on the planet. SquaredUp simply provides the context. SquaredUp utilizes your existing SCOM agents so you can map and monitor all your enterprise applications without the need for any new agents, databases or infrastructure. As always, a picture says a thousand words, so below is a quick snap shot of our unique Visual Application Discovery & Analysis (VADA) feature in action.

Beautiful isn't it? Better still, those sexy application diagrams could be yours for just a few thousand dollars each year. Product messaging aside, the point I'd like to hammer home here is that context is king. SquaredUp isn't a new data source, we simply put all your existing data into the context of key applications and services; helping ITOps cut through the noise and focus on the alerts that matter most.
Wrapping up
The key takeaway I'd like you to take from this blog, isn’t that you should download SquaredUp (although if you want to that would be great ?), it should be that ITOps needs to do a better job providing themselves - and the business - with context. You need to rethink your monitoring strategy.
For too long enterprise monitoring efforts have focused too heavily on infrastructure – your business cares about applications, not servers and disks – yet most ITOps monitoring strategies are built from the ground up. Starting from low-level component issues and never really moving beyond there.
Once you've added context to your reporting, you'll be well on your way to solving the issue of alert fatigue.